In cloud environments, managing long-running, stateful workloads across spot instances can be a complex task. Spot instances offer substantial cost savings (up to 90%!), but they come with a trade-off: they can be terminated at any time with minimal warning, often interrupting critical tasks mid-way. This disrupts processes like machine learning training, data analysis, and scientific simulations, potentially leading to lost work, manual restarts, and higher costs due to reprocessing.
For engineers looking to leverage the savings of spot instances without sacrificing uptime, Cedana offers an automated, resilient solution. Using Cedana’s Save, Migrate, Resume (SMR) API, engineers can checkpoint their application’s state, seamlessly transfer it to a new instance, and resume operations without manual intervention. This guide will walk you through Cedana’s unique capabilities, demonstrating how SMR enables cost-effective and interruption-free workload management on spot instances, from setup to real-world applications in finance, data science, and research.
What Does Cedana Do?
Cedana brings live migration capabilities to containerized, stateful workloads through its Save, Migrate, Resume (SMR) REST API. This allows you to checkpoint an application’s state, transfer it to another instance, and resume operations without restarting the process. Cedana’s checkpoint and restore capabilities ensure minimal disruption, making it ideal for environments like data science, financial modeling, and cloud-native applications where consistent uptime is essential.
Why is SMR important?
Spot instances are a common cost-saving strategy, saving up to 10x on compute costs. However, they are limited to shorter duration jobs. These instances are offered at a reduced price but can be terminated (revoked) at any moment with limited warning, also known as a preemption notice or termination notice, often preceded by a two-minute warning. This interrupts and leads to loss of work for workloads that run continuously over long periods, such as training machine learning models or running large data processes. Spot prices fluctuate based on demand, making it necessary to handle these spot instance price changes effectively. Current solutions to managing spot instances are limited to manually addressing interruptions, typically resulting in the entire task restarting from the beginning. In some cases, users spend time and overhead modifying their task to save state to disk periodically and upon termination, manually resuming the workload on a new instance, which is time-consuming, complex, and limited to specific workloads. These approaches lead to increased cloud costs, manual overhead, and wasted time.
Before diving into how Cedana addresses this challenge, let’s first understand what spot instances are and how they work.
Understanding Spot Instances
Spot instances are a cost-saving resource provided by cloud providers, offering compute power at up to a 10x discount. However, they come with a trade-off: these instances can be terminated when demand for standard instances increases. This makes them suitable for workloads that can handle interruptions but are challenging for long-running tasks.
Typical workloads suited for spot instances include short duration batch processing, machine learning training, and testing environments—any workload that can tolerate intermittent interruptions. While cost-effective, managing these interruptions is a challenge Cedana resolves by offering live migration across different instances. Cedana expands the types of jobs that can be used effectively with short to long duration workloads.
Key lifecycle stages of spot instances:
- Request: Users request spot instances, specifying configurations.
- Interruption Notice: The provider can notify users of an imminent interruption (typically 2-minute warning).
- Termination: The instance is terminated unless migrated.
Without a tool like Cedana, users can’t effectively use spot instances for long duration jobs because preemptions result in downtime, lost work, higher costs and manual overhead, forcing developers to restart workloads.
Why Integrate Cedana for Workload Live Migration?
Cedana enables workload migration, across spot instances. This ensures workloads continue running smoothly, even when a spot instance is interrupted. Without Cedana, engineers would have to deal with these interruptions manually, potentially leading to higher cloud computing costs. This could involve writing custom scripts to monitor instance terminations, code modifications to capture the application’s state, and transferring it to another instance. For example, engineers might set up cron jobs or monitoring systems that alert them when an instance is about to be preempted and then use shell scripts to save the current state of the application. They’d also have to restart the workload on a new instance, often resulting in downtime or lost progress.
How Cedana Solves Spot Instance Interruptions
Spot instance interruptions have long been an issue for high-availability environments. These interruptions impact the stability of running workloads, but Cedana solves this by providing
Hands-On: Migrating a Workload with Cedana on GCP GKE During Spot Interruption
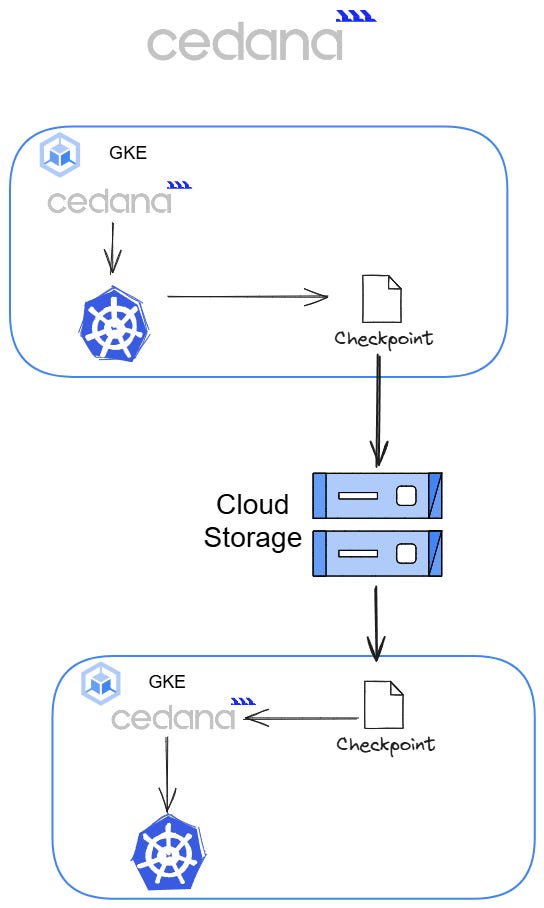
As an infrastructure engineer, you often have multiple critical applications or services running on spot instances within your Kubernetes (K8s) cluster. These workloads could range from web services to resource-intensive machine learning models. One common scenario is using spot instances to handle tasks like training models with XGBoost, which can take hours to complete. Spot instances offer great cost savings but come with the risk of interruptions, meaning your model could lose progress if the instance is preempted.
This section will demonstrate how to use Cedana to prevent such disruptions. We'll walk through migrating an XGBoost machine learning model running on GCP’s Google Kubernetes Engine (GKE)from one spot instance to another during an interruption. The model's state will be checkpointed and stored in a Google Cloud Storage bucket, then restored with minimal downtime.
Note: You can use Cedana SMR on all major cloud providers, and can even SMR across providers.
Step 1: Set Up Google Kubernetes Engine (GKE)
Create a GKE Cluster:
gcloud container clusters create cedana-cluster --zone us-central1-a --image-type UBUNTU_CONTAINERD
Make sure to select the Image type as Ubuntu with containerd.
For this example, we are creating a brand new cluster. However, if you already have an existing Kubernetes cluster that runs on GKE, feel free to skip this step and proceed directly to the migration setup. Make sure that the GKE image is not a Container-Optimized OS or else Cedana won’t work.
Set Cluster Context:
gcloud container clusters get-credentials cedana-cluster --zone us-central1-a
Step 2: Install Cedana on GKE
git clone https://github.com/cedana/cedana-helm-charts --depth 1helm install cedana ./cedana-helm-charts/cedana-helm --create-namespace -n cedanacontroller-system

Make sure to edit the values.yaml file with your values.
Once Cedana is installed, you will see its helm-manager and helm-helper pods deployed successfully.
Step 3: Deploy XGBoost Workload on a Spot Instance
Deploy XGBoost Workload: Create a pod that runs XGBoost and trains a model:
apiVersion: v1
kind: Pod
metadata:
name: xgboost-light-pod
labels:
app: xgboost
spec:
containers:
- name: xgboost-container
image: python:3.8-slim
command: ["/bin/bash", "-c"]
args: ["pip install xgboost scikit-learn && python3 -c 'import xgboost as xgb; from sklearn.datasets import fetch_california_housing; from sklearn.model_selection import train_test_split; data = fetch_california_housing(); X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2); train_dmatrix = xgb.DMatrix(data=X_train, label=y_train); test_dmatrix = xgb.DMatrix(data=X_test, label=y_test); params = {\"objective\": \"reg:squarederror\", \"max_depth\": 3, \"eta\": 0.3}; model = xgb.train(params, train_dmatrix, num_boost_round=10000); print(model.predict(test_dmatrix))' && tail -f /dev/null"]
Apply this YAML:
kubectl apply -f xgboost-pod.yaml
Step 4: Checkpoint the Workload and Store it in GCS
Now that everything has been set up we can now port forward the cedana-helm-helper and perform a checkpoint.
kubectl port-forward "cedana-cedana-helm-manager-<id>" -n cedanacontroller-system 1324:1324
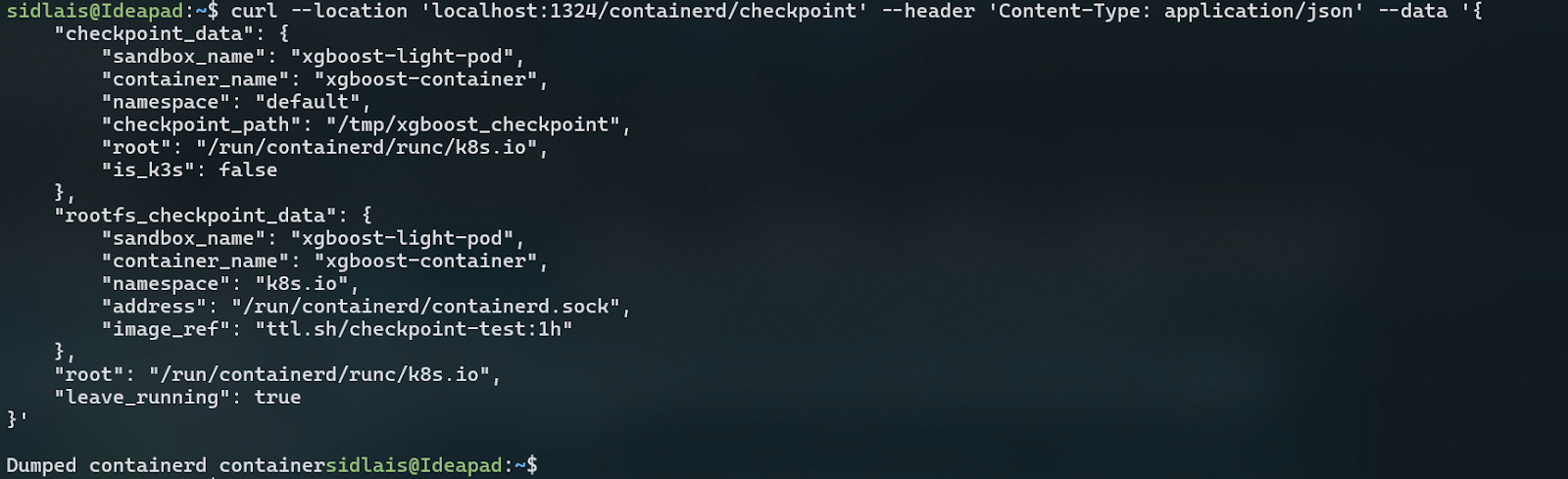
Perform a curl to the helm-manager with the necessary information about the pod that you want to checkpoint. Cedana will make a checkpoint of the pod on the given path and create an image that will be temporarily hosted at
curl --location 'localhost:1324/containerd/checkpoint' --header 'Content-Type: application/json' --data '{
"checkpoint_data": {
"sandbox_name": "xgboost-light-pod",
"container_name": "xgboost-container",
"namespace": "default",
"checkpoint_path": "/tmp/xgboost_checkpoint",
"root": "/run/containerd/runc/k8s.io",
"is_k3s": false
},
"rootfs_checkpoint_data": {
"sandbox_name": "xgboost-light-pod",
"container_name": "xgboost-container",
"namespace": "k8s.io",
"address": "/run/containerd/containerd.sock",
"image_ref": "ttl.sh/checkpoint-test:1h"
},
"root": "/run/containerd/runc/k8s.io",
"leave_running": true
}'
- Simulate Spot Interruption: Preempt the spot instance by terminating it.
Find the node in which the checkpoint is stored:
kubectl get pod xgboost-light-pod -o wide
SSH into the specific node and make a copy of the checkpoint in GCS:
gsutil cp /tmp/xgboost_checkpoint gs://your-bucket-name/xgboost_checkpoint.tar
Step 5: Restore the Workload from GCS
Now that we’ve checkpointed the XGBoost workload to a Google Cloud Storage (GCS) bucket, the next step is to restore it on a
gsutil cp gs://your-bucket-name/xgboost_checkpoint /tmp/xgboost_checkpoint.tar
Launch the restore pod:
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: xgboost-restore
spec:
replicas: 1
selector:
matchLabels:
app: xgboost-restore
template:
metadata:
labels:
app: xgboost-restore
spec:
nodeSelector:
checkpointed: "true"
containers:
- name: xgboost-restore
image: ttl.sh/checkpoint-test:1h
imagePullPolicy: Always
command: ["sleep"]
args: ["infinity"]
EOF
Now let’s restore our pod in the new cluster. First, we need to create a sleeping pod using the image of the checkpointed pod. This sleeping state allows Cedana to attach the checkpointed data smoothly before the workload resumes, ensuring a stable restoration environment.
curl --location --request POST 'localhost:1324/restore' \
--header 'Content-Type: application/json' \
--data '{
"checkpoint_data": {
"sandbox_name": "xgboost-light-pod-<pod-id>",
"container_name": "xgboost-container",
"namespace": "default",
"checkpoint_path": "/tmp/xgboost_checkpoint",
"root": "/run/containerd/runc/k8s.io",
"is_k3s": false
}
}'
Step 6: Verify the Migration
After restoring the workload, confirming that the model continues training without any data loss or reset is important. By checking the progress, you can verify that Cedana’s migration process preserved the model's state exactly as it was before the interruption. You should see the model resume from where it left off, proving that the migration worked effectively. This step is key to ensuring the migration was successful and the workload continued without disruption.
Real-World Use Cases of Cedana
Cedana’s SMR (Save, Migrate, Resume) technology can bring significant advantages to industries that depend on long-running, computationally heavy workloads. Below are some key examples:
- Data Analytics: In data-driven industries, analytics workloads can often run for hours or even days, processing large datasets for insights. When using spot instances, unexpected interruptions could halt the progress of these jobs, forcing data engineers to restart from scratch. Cedana helps reduce this risk by enabling checkpointing and restoring these analytics jobs across different instances with minimal downtime.By migrating workloads smoothly when a spot instance is preempted, Cedana eliminates the need to restart jobs, saving substantial compute time and cost. By managing Spot Instance prices effectively, data analytics workloads can also benefit from steep discounts offered by Cloud Service Providers. For example, in Google Cloud’s data pipeline jobs, companies can integrate Cedana to manage preemptible instances and ensure continuous processing.
- Financial Modeling: The financial services industry frequently runs sophisticated simulations for risk analysis, portfolio optimization, and fraud detection tasks. These workloads often require large-scale, long-running computational power. Spot instances are commonly used here due to their cost efficiency. However, preemptions and interruption notices can disrupt these workloads, causing delays and increasing computational costs.Cedana's SMR technology ensures that these models continue running uninterrupted by migrating workloads from preempted instances to new instances. This leads to considerable time savings, reducing downtime and avoiding the cost of rerunning simulations from the beginning. Some financial services companies utilize cloud-based solutions forportfolio risk calculations, which would benefit greatly from Cedana’s SMR. Cedana allows financial companies to take advantage of steep discounts in spot prices while keeping critical applications running.
- Scientific Simulations: In fields such as bioinformatics, climate modeling, and particle physics, scientific simulations often run continuously for days or weeks. These simulations can be costly if interrupted, requiring researchers to restart them from the beginning. Using Cedana’s checkpointing and restoration capabilities on spot instances, research teams can save both time and resources by avoiding interruptions due to preemptions, interruption notices, and termination notices. The ability to manage Spot VMs and cloud computing resources while achieving additional savings in cloud spending is a key advantage for scientific workloads.One example includes scientific workloads that utilize Google Cloud's HPC (High-Performance Computing) services. Cedana can be implemented to ensure that any interruption is managed smoothly through automated migration, preventing resource wastage in long-term simulations.
Benefits Observed: By enabling SMR, Cedana reduces human intervention, ensuring that workloads can be migrated fully automatically. This reduces operational costs associated with monitoring and restarting workloads. Moreover, companies can achieve significant cost savings by utilizing spot instances without the risk of workload disruptions. In industries where every minute of compute time is critical, such as financial modeling or scientific research, Cedana’s SMR provides a critical layer of resilience, reducing the potential costs of interruptions and improving overall system performance.
Conclusion
By the end of this guide, engineers should have a clear understanding of spot instances, their benefits, and the risks of interruptions they can bring. More importantly, they’ll see how Cedana steps in to make these risks manageable. With Cedana’s Save, Migrate, Resume (SMR) feature, migrating workloads between spot instances becomes effortless, ensuring uninterrupted tasks without manual intervention. If you're ready to simplify your spot instance management and keep your workloads running smoothly, Cedana is here to help.
FAQs
- What are the benefits of live migration?
Live migration allows applications to continue running without noticeable downtime, even when moving workloads between servers or instances. This is critical for maintaining high availability and reducing the risk of service disruption. With tools like Cedana, live migration becomes fully automated, reducing the need for manual intervention and allowing businesses to save both time and costs while ensuring workload continuity.
- What is the process of live migration?
Live migration involves saving the current state of an application or workload, transferring it to another server or instance, and resuming it without disruption. This process typically includes checkpointing the running application, migrating the data to a new environment, and resuming the workload from the saved state. Cedana’s SMR (Save, Migrate, Resume) process automates this for containerized workloads, making it more efficient.
- What are the 3 advantages of migration?
- Cost Savings: Migrating workloads to cost-effective cloud solutions like spot instances helps companies reduce infrastructure costs.
- Improved Uptime: Automated migration ensures high availability by moving workloads to different preemptible instances before failures occur.
- Scalability: Migration allows businesses to easily scale their applications by moving workloads across more powerful resources.
- How long does live migration take?
The time taken for live migration depends on the workload size and the network speed between servers. Typically, it takes just a few minutes to migrate smaller workloads, but larger data-intensive applications may take longer. Cedana's live migration system is designed to minimize this time by using efficient checkpointing and restoration processes, ensuring minimal downtime.